Executing Untrusted Code in Serverless Environments: A Telegram Bot for Running C and C++ Code on Cloud Run
Intro
I enjoy experimenting and writing Telegram bots for programming groups I participate in. In two groups, people frequently ask about C or C++ code, seeking help, examples, and more. Instead of using online tools like Godbolt (Compiler Explorer), they prefer sending their code directly in messages.
I had previously created such a bot using a Flask webserver, which communicated with another container through JSON-RPC. It worked well but occasionally had issues.
With the rise of LLM, I switched to using OpenAI, but many users complained about the unconventional results, which was amusing.
Recently, while working on a project named Carimbo, I started exploring WebAssembly. I realized it could be ideal for running untrusted code. Initially, I considered using isolated-vm with WebAssembly, but I was quite satisfied with Wasmtime. It offered options to limit CPU time and RAM usage, among other features.
Cgroups
Any experienced developer would likely suggest using cgroups and namespaces, which are indeed superior options. However, I prefer not to incur the costs of VMs or keep a machine running 24/7 at my home. This is primarily because Cloud Run, based on Docker, already utilizes cgroups, and to my knowledge, nested cgroups aren’t possible.
Cloud Run offers me several advantages. Without delving into too much detail, it’s a serverless platform built on top of Kubernetes, employing gVisor for an added security layer. You don’t need to handle Kubernetes directly, but the option for fine-tuning is available, which I will discuss in this article.
The Bot
Unlike in my previous work Hosting Telegram bots on Cloud Run for free, this time I will not use Flask, but instead, I will directly employ Starlette. Starlette is an asynchronous framework for Python. One of the main reasons for this migration is to utilize asyncio, which will enable handling more requests. Additionally, the python-telegram-robot library has shifted to this asynchronous model, aligning with this change.
Let’s start with the Dockerfile.
FROM python:3.12-slim-bookworm AS base
ENV PIP_DISABLE_PIP_VERSION_CHECK 1
ENV PYTHONUNBUFFERED 1
ENV PYTHONDONTWRITEBYTECODE 1
ENV EMSDK=/emsdk
ENV PATH=/emsdk:/emsdk/upstream/emscripten:/opt/venv/bin:$PATH
FROM base AS builder
RUN python -m venv /opt/venv
COPY requirements.txt .
RUN pip install --no-cache-dir --requirement requirements.txt
FROM base
WORKDIR /opt/app
# Let's steal this entire directory from the official Emscripten image.
COPY --from=emscripten/emsdk:3.1.49 /emsdk /emsdk
COPY --from=builder /opt/venv /opt/venv
COPY . .
RUN useradd -r user
USER user
# Instead of Gunicorn, we will use Uvicorn, which is an ASGI web server implementation for Python.
CMD exec uvicorn main:app --host 0.0.0.0 --port $PORT --workers 8 --timeout-keep-alive 600 --timeout-graceful-shutdown 600
The main differences are that we steal an entire directory from the Emscripten Docker image, which saves us from having to build in the image, which is excellent. We also use Uvicorn, an ASGI web server that allows direct use of asyncio.
Now let’s see how it goes with handling the incoming requests.
def equals(left: str | None, right: str | None) -> bool:
"""
Compare two strings using a consistent amount of time to avoid timing attacks.
"""
if not left or not right:
return False
if len(left) != len(right):
return False
for c1, c2 in zip(left, right):
if c1 != c2:
return False
return True
async def webhook(request: Request):
"""
Entry point for requests coming from Telegram.
"""
if not equals(
request.headers.get("X-Telegram-Bot-Api-Secret-Token"),
os.environ["SECRET"],
):
# This section prevents false calls, only this application and Telegram know the secret.
return Response(status_code=401)
payload = await request.json()
# Where the bot becomes operational, the JSON is passed to the application, which in turn processes the request.
async with application:
await application.process_update(Update.de_json(payload, application.bot))
return Response(status_code=200)
app = Starlette(
routes=[
Route("/", webhook, methods=["POST"]),
],
)
Finally, we have the handler for messages that start with /run.
async def on_run(update: Update, context: ContextTypes.DEFAULT_TYPE) -> None:
message = update.message.reply_to_message or update.message
if not message:
return
text = message.text
if not text:
return
text = text.lstrip("/run")
if not text:
await message.reply_text("Luke, I need the code for the Death Star's system.")
return
try:
# All the code is asynchronous, while the 'run' function is not. Therefore, we execute it in a thread.
coro = asyncio.to_thread(run, text)
# We execute the thread as a coroutine and limit its execution to 30 seconds.
result = await asyncio.wait_for(coro, timeout=30)
# Below, we prevent flooding in groups by placing very long messages into a bucket and returning the public URL.
if len(result) > 64:
blob = bucket.blob(hashlib.sha256(str(text).encode()).hexdigest())
blob.upload_from_string(result)
blob.make_public()
result = blob.public_url
# Respond to the message with the result, which can be either an error or a success.
await message.reply_text(result)
except asyncio.TimeoutError:
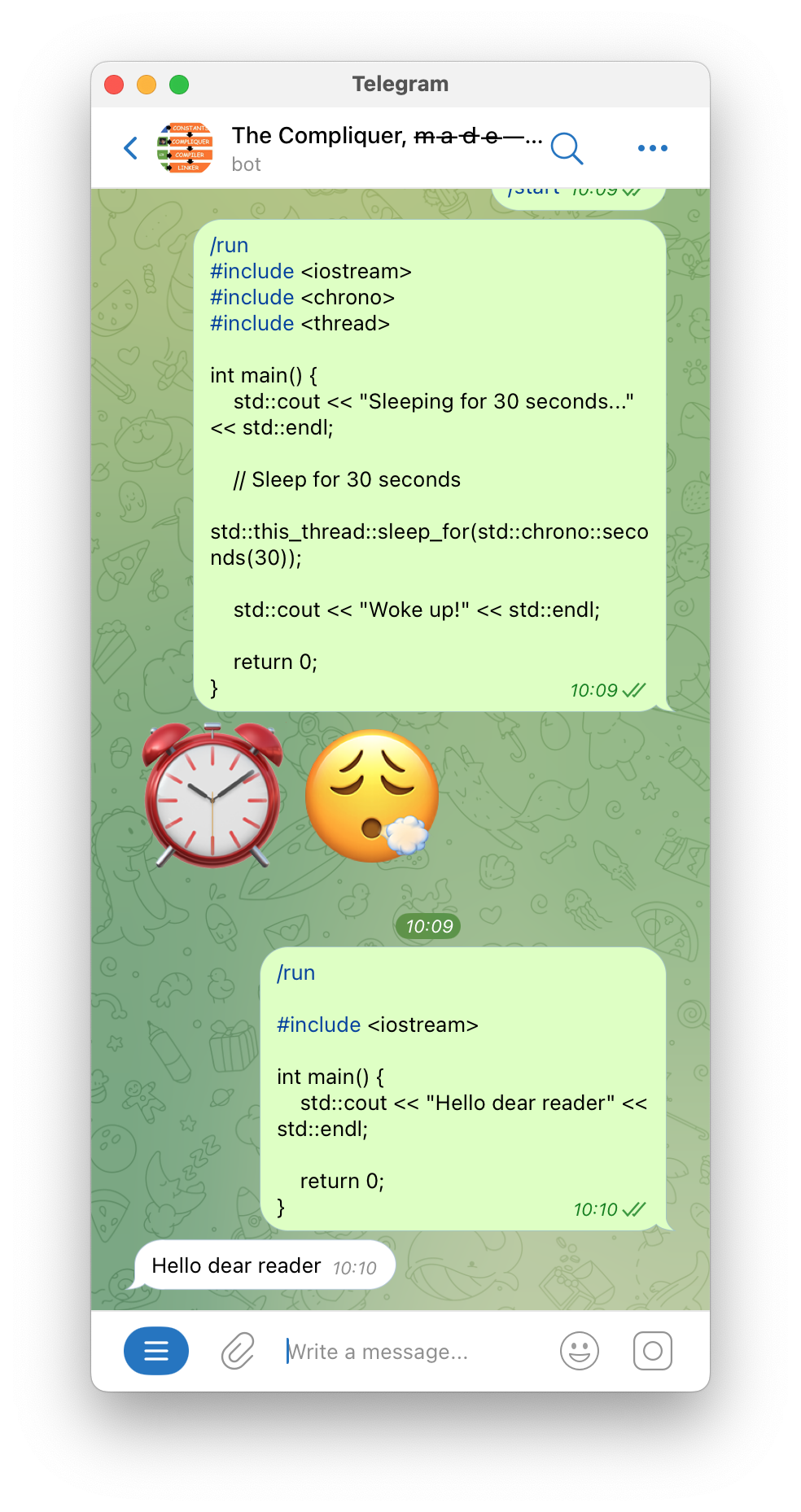
# If the code exceeds the time limit or takes too long to compile, we return some emojis.
await message.reply_text("⏰😮💨")
Running Untrusted Code
Each request to execute code is compiled using em++, an ‘alias’ for clang++, targeting WebAssembly, and then executed with the WASI runtime. Each execution runs separately and in a thread-safe manner in its own directory. While I could limit CPU usage (fuel) and memory usage, as indicated by the commented lines, in my case I opted for a container with 4GB of RAM and 4 vCPUs, which is more than sufficient given that I configured Run to accept only 8 connections per instance.
def run(source: str) -> str:
with TemporaryDirectory() as path:
os.chdir(path)
with open("main.cpp", "w+t") as main:
main.write(source)
main.flush()
try:
# Compile it.
result = subprocess.run(
[
"em++",
"-s",
"ENVIRONMENT=node",
"-s",
"WASM=1",
"-s",
"PURE_WASI=1",
"main.cpp",
],
capture_output=True,
text=True,
check=True,
)
if result.returncode != 0:
return result.stderr
# Run it.
with open("a.out.wasm", "rb") as binary:
wasi = WasiConfig()
# Store the output in a file.
wasi.stdout_file = "a.out.stdout"
# Store the errors in a file.
wasi.stderr_file = "a.out.stderr"
config = Config()
# config.consume_fuel = True
engine = Engine(config)
store = Store(engine)
store.set_wasi(wasi)
# Limits the RAM.
# store.set_limits(16 * 1024 * 1024)
# Limits the CPU.
# store.set_fuel(10_000_000_000)
linker = Linker(engine)
linker.define_wasi()
module = Module(store.engine, binary.read())
instance = linker.instantiate(store, module)
# `_start` is the binary entrypoint, also known as main.
start = instance.exports(store)["_start"]
assert isinstance(start, Func)
try:
start(store)
except ExitTrap as e:
# If exit code is not 0, we return the errors.
if e.code != 0:
with open("a.out.stderr", "rt") as stderr:
return stderr.read()
# If no errors, we return the output.
with open("a.out.stdout", "rt") as stdout:
return stdout.read()
except subprocess.CalledProcessError as e:
return e.stderr
except Exception as e: # noqa
return str(e)
Deploy
In the past, I always used Google’s tools for deployment, but this time I tried building the Docker image in GitHub Action, which gave me two huge advantages.
- Cache: I don’t know why, but I never got the cache to work in Cloud Build. With GitHub, it’s just a matter of using a flag.
- Modern Docker syntax usage: In Cloud Build, it’s not possible to use heredoc, for example.
- Speed: I know it’s possible to upgrade the Cloud Build machine, but that costs money, and on GitHub, I have a quite generous free quota.
name: Deploy on Google Cloud Platform
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Authenticate to Google Cloud
uses: google-github-actions/auth@v1
with:
credentials_json: $
- name: Set up Google Cloud SDK
uses: google-github-actions/setup-gcloud@v1
with:
project_id: $
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Authenticate Docker
run: gcloud auth configure-docker --quiet $-docker.pkg.dev
- name: Build And Push Telegram Service
uses: docker/build-push-action@v5
with:
context: .
push: true
tags: $/$:$
cache-from: type=gha
cache-to: type=gha,mode=max
- name: Deploy Telegram Service to Cloud Run
env:
TELEGRAM_SERVICE_NAME: $
REGION: $
REGISTRY: $
GITHUB_SHA: $
TELEGRAM_TOKEN: $
SECRET: $
BUCKET: $
run: |
cat <<EOF | envsubst > service.yaml
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: "$TELEGRAM_SERVICE_NAME"
labels:
cloud.googleapis.com/location: "$REGION"
spec:
template:
metadata:
annotations:
run.googleapis.com/execution-environment: "gen2"
run.googleapis.com/startup-cpu-boost: "true"
run.googleapis.com/cpu-throttling: "true"
autoscaling.knative.dev/maxScale: "16"
spec:
containerConcurrency: "1"
timeoutSeconds: "60"
containers:
- image: "$REGISTRY/$TELEGRAM_SERVICE_NAME:$GITHUB_SHA"
name: "$TELEGRAM_SERVICE_NAME"
resources:
limits:
cpu: "4000m"
memory: "4Gi"
env:
- name: TELEGRAM_TOKEN
value: "$TELEGRAM_TOKEN"
- name: SECRET
value: "$SECRET"
- name: BUCKET
value: "$BUCKET"
EOF
gcloud run services replace service.yaml
rm -f service.yaml
Conclusion
Try here: https://t.me/neo_compiler_bot or @neo_compiler_bot on Telegram.
Source code: https://github.com/skhaz/neo-compiler-and-runner.